

其中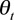 为字符串分片t的覆盖率,
为字符串分片t的覆盖率,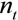 为包含字符串分片t的数据包个数, N为总的数据包个数。
为包含字符串分片t的数据包个数, N为总的数据包个数。
One-Way Hash是这样一种针对字符串的Hash算法,它用字符串的Hash值作为这个字符串在Hash表中的下标,每一个Hash值进行取模运算 (mod)对应到数组中的一个位置,这样只要比较这个字符串的哈希值对应的位置有没有被占用,就可以得到最后的结果了,这种方法的速度是最快的O(1)。对两个字符串在哈希表中对应的位置相同的问题,One-Way Hash解决问题的基本原理就是:在哈希表中不是用一个哈希值而是用三个哈希值来校验字符串。 假如说两个不同的字符串经过一个哈希算法得到的入口点一致有可能,但用三个不同的哈希算法算出的入口点都一致,那几乎可以肯定是不可能的事了,这个几率是1:18889465931478580854784,大概是10的22.3次方分之一,对于普通程序来说已经远远足够了。
第四,字符串分片的重组。经过第三步的处理我们就可以得到若干覆盖率大于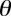 的字符串分片,我们需要将这些零散的字符串按照位置信息进行重新组合,将位置连续的字符串合并到一起,考虑到过短的特征字符串没有实际应用意义,经过长期的观察实验,可以设定一个阈值,只有长度超过这个阈值的特征字串才能被用作特征码,以表1为例,以2个字节长度进行分片,设置阈值为4个字节,那么合并后就只剩下一个符合条件的字串,我们就将这个字串作为一个特征码。
的字符串分片,我们需要将这些零散的字符串按照位置信息进行重新组合,将位置连续的字符串合并到一起,考虑到过短的特征字符串没有实际应用意义,经过长期的观察实验,可以设定一个阈值,只有长度超过这个阈值的特征字串才能被用作特征码,以表1为例,以2个字节长度进行分片,设置阈值为4个字节,那么合并后就只剩下一个符合条件的字串,我们就将这个字串作为一个特征码。
第五,特征码的重验证以及去除冗余。这种提取特征码的方法虽然效率很高,速度很快,但作为交换牺牲了一些准确性,带来了一些冗余信息,这些冗余信息主要是跟时间或者当前流媒体播放的节目相关的一些内容,这些内容只会在某一时间段内出现的比较频繁,而在之前或之后的时间内不会或很少出现,利用一个重验证的过程就可以去除这些冗余,同时也对特征码进一步的提纯,并起到一个校验的效果。

特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。
北京一学校启动雾霾天远程教学 停课时视频教学2013/12/30
湖南职业院校推广空间教学2012/02/06
新兴教育“暗战”学校教育2011/05/03
扬州大学:借力大数据构建绿色校园信息化格局2017/06/12
教育信息化引领智慧校园建设2015/08/28
福建南安市:政采助力教育信息化建设2015/08/21
天津职业大学加快推进校园信息化建设2014/02/19




投稿、转载或合作,请联系:eduinfo#cernet.com (请将#替换为@)
版权所有:中国教育和科研计算机网网络中心 CERNIC,CERNET
京ICP备15006448号-16 京网文[2017]10376-1180号  京公网安备 11040202430174号
京公网安备 11040202430174号
![京网文[2017]10376-1180号](/images/indexnew/www1024.jpg){kind=link}
关于假冒中国教育网的声明 | 有任何问题与建议请联络:Webmaster@cernet.com